СОДЕРЖАНИЕ
ВВЕДЕНИЕ 7
1 ОБРАБОТКА ДАННЫХ С ИСПОЛЬЗОВАНИЕМ СИСТЕМ ИСКУССТВЕННОГО ИНТЕЛЛЕКТА. 10
1.1 СИСТЕМЫ СБОРА И ОБРАБОТКИ АНКЕТНЫХ ДАННЫХ 10
1.2 СИСТЕМЫ ИСКУССТВЕННОГО ИНТЕЛЛЕКТА. 28
1.3 ПРОГРАММНОЕ ОБЕСПЕЧЕНИЕ ДЛЯ СИСТЕМ ИСКУССТВЕННОГО ИНТЕЛЛЕКТА 41
1.4 ВЫВОДЫ ПО РАЗДЕЛУ 47
2 РАЗРАБОТКА МЕТОДИКИ ИСПОЛЬЗОВАНИЯ СИСТЕМ ИСКУССТВЕННОГО ИНТЕЛЛЕКТА ПРИ ОБРАБОТКЕ АНКЕТНЫХ ДАННЫХ. 48
2.1 ПРИМЕНЕНИЕ СИСТЕМ ИСКУССТВЕННОГО ИНТЕЛЛЕКТА ПРИ СБОРЕ И ОБРАБОТКЕ ДАННЫХ 48
2.2 СИСТЕМЫ СБОРА И ООБРАБОТКИ ДАННЫХ 50
2.3 ВЫВОДЫ ПО РАЗДЕЛУ 56
3 ПРИМЕНЕНИЕ СИСТЕМ ИСКУССТВЕННОГО ИНТЕЛЛЕКТА ПРИ СБОРЕ И ОБРАБОТКЕ АНКЕТНЫХ ДАННЫХ 58
3.1 ОБЩАЯ ХАРАКТЕРИСТИКА ОРГАНИЗАЦИИ 58
3.2 СИСТЕМА СБОРА И ОБРАБОТКИ ДАННЫХ ОПРОСА СТУДЕНТОВ «AS-IS». 77
3.3 СИСТЕМА СБОРА И ОБРАБОТКИ ДАННЫХ ОПРОСА СТУДЕНТОВ «TO-BE».. 82
3.4 ЭКОНОМИЧЕСКО ОБОСНОВАНИЕ. 84
3.5 ВЫВОДЫ ПО РАЗДЕЛУ 95
ЗАКЛЮЧЕНИЕ. 96
СПИСОК ИСПОЛЬЗОВАННЫХ ИСТОЧНИКОВ. 98
ВВЕДЕНИЕ
Обработка анкетных данных – трудоёмкий процесс, особенно в учебных заведениях, ведь необходимо собрать данные с многочисленного числа студентов. В результате сбора данных интервьюер имеет большое количество анкет. Ответы на опрос не подлежат отбору, то есть какие из них следует учитывать, а какие бесполезны, так потребуется дополнительные трудовые ресурсы, что означает увеличение затрат.
Выбор темы диссертации обуславливается сложившейся проблемой, описанной выше. Для автоматизации процесса отбора анкетных данных были разработаны и обучены алгоритмы машинного обучения, классификаторы, которые определяют для заполненной анкеты: будет ли она учтена для анализа эффективности учебного процесса.
Объект исследования - система сбора и обработки анкетных данных отдела диспетчеризации ВШЭМ УрФУ.
Предмет исследования - автоматизация процесса ранжирования анкетных данных по релевантности.
Целью данной работы является автоматизация процесса отбора анкетных данных в дистрибутиве Python Anaconda с использованием алгоритмов машинного обучения.
1 ОБРАБОТКА ДАННЫХ С ИСПОЛЬЗОВАНИЕМ СИСТЕМ ИСКУССТВЕННОГО ИНТЕЛЛЕКТА
1.1 СИСТЕМЫ СБОРА И ОБРАБОТКИ АНКЕТНЫХ ДАННЫХ
Анкета – основной инструмент количественных исследований.
Сбор данных осуществляется с помощью метода анкетирования, который используется в рамках определенного социального исследования и предполагает, что целевые группы респондентов самостоятельно заполнят анкеты и возвратят их интервьюеру [7].
Цель анкетирования заключается в выявлении различных фактов и тенденций.
В результате процесса анкетирования собирают большой объем данных, что обуславливает необходимость использования соответствующих программных средств для обработки этих данных.
В настоящее время набирает популярность статистический программный комплекс SPSS [8].
Общая информация о пакете SPSS и его структуре
Пакет SPSS (Statistical Package for the Social Sciences - cтатистический пакет для социальных наук) изначально1 был разработан как компьютерная программа для статистической обработки данных, предназначенная для проведения прикладных исследований в социальных науках.
В 2009 г. пакет стал называться PASW Statistics (Predictive Analytics SoftWare – интеллектуальное аналитическое программное обеспечение) [11].
С июля 2009 г. пакет сопровождается фирмой IBM (International Business Machines) под именем IBM SPSS Statisics.
В 2013 г. планируется выход очередной версии пакета - IBM SPSS Statistics 22, работающей под управлением различных операционных систем - Windows, MacOsX, Linux [14].
Имея модульную структуру, пакет SPSS обеспечивает комплексную статистическую обработку – от планирования до управления данными, выполнения анализа и представления результатов. Мощные средства анализа и обработки данных с развитым графическим интерфейсом, удобные меню и простые диалоговые окна существенно упрощают работу пользователя [10].
Основные блоки SPSS:
-
редактор данных - гибкая система, внешне похожая на электронную таблицу, служит для определения, ввода, редактирования и просмотра данных;
-
визуализатор - средство просмотра, упрощающее отображение результатов, позволяющее показывать и скрывать отдельные элементы вывода, изменять порядок вывода результатов, перемещать готовые к презентации таблицы и диаграммы в другие приложения и получать их из других программных приложений;
1.2 СИСТЕМЫ ИСКУССТВЕННОГО ИНТЕЛЛЕКТА
Искусственный интеллект – это свойство автоматических вычислительных систем исполнять отдельные функции интеллекта человека, например, выбирать и принимать оптимальные и эффективные решения на основе полученного опыта и рационального анализа внешних воздействий [16].
Под мыслительным процессом или интеллектуальной деятельностью понимаем деятельность мозга, которая направлена на решение задач, требующих умственных усилий. Интеллект или мышление напрямую связаны с решением таких задач, как логический анализ, распознавание ситуаций, доказательство теорем, планирование поведения, а также управление в условиях неопределенности. Характерными чертами интеллекта, которые проявляются в процессе решения задач, являются следующие: способность к обобщению, и аккумулированию опыта (знаний и навыков), обучению и адаптации к изменяющимся условиям в процессе решения задач. Мозг может решать разнообразные задачи благодаря вышеперечисленным качествам, а также быть мобильным, легко перестраиваться с решения одной задачи на другую. Следовательно, мозг, который наделен интеллектом, является универсальным средством решения широкого спектра задач, в том числе неформализованных, для которых нет заранее известных методов решения [17].
Безусловно, можно исключить задачи, которые не решаются стандартными методами, из класса интеллектуальных. В качестве примеров таких задач могут выступать вычислительные задачи: решение системы линейных алгебраических уравнений, численное интегрирование дифференциальных уравнений и прочее. Решением подобных задач выступают алгоритмы, которые представляют собой определенную последовательность элементарных операций; данная последовательность может быть легко реализована в виде компьютерной программ. Хотя для широкого класса интеллектуальных задач, таких, игра в шахматы, как распознавание образов, доказательство теорем и т.п., напротив, это формальное разбиение процесса поиска решения на отдельные элементарные шаги часто оказывается весьма затруднительным, даже если само их решение является поверхностным [15].
1.3 ПРОГРАММНОЕ ОБЕСПЕЧЕНИЕ ДЛЯ СИСТЕМ ИСКУССТВЕННОГО ИНТЕЛЛЕКТА
В рамках данного направления разрабатываются специальные языки для решения интеллектуальных задач, в которых упор делается на преобладание логической и символьной обработки над вычислительными процедурами. Языки ориентированы на символьную обработку информации: PROLOG, РЕФАЛ, LISP, СLIPS, PYTHON и прочие. LISP, один из старейших языков более высокого уровня, который обрабатывает списки. Prolog основан на логике. Сегодня популярны C ++ и Python. Также существует специальное программное обеспечение для разработки экспертных систем. Помимо этого, создаются пакеты прикладных программ, которые ориентированы на промышленную разработку интеллектуальных систем, или программные инструментарии искусственного интеллекта [2].
Несколько крупных пользователей ИИ предоставляют платформы для разработки, в том числе Amazon, Baidu, Google, IBM и Microsoft. Данными компаниями предложены заранее обученные системы как стартовая точка для некоторых распространенных приложений, например, распознавание голоса. Поставщики процессоров, такие как Nvidia и AMD, тоже предлагают определенную поддержку [3].
Структура и свойства программного обеспечения
Основными составными частями программного обеспечения (ПрО) систем искусственного интеллекта (СИИ) являются:
-
программно-аппаратные средства СИИ;
-
программные средства представления знаний в СИИ;
-
языки программирования и среды функционирования СИИ;
-
инструментальные программные средства создания СИИ и др [20].
Основными особенностями ПрО, которые существенно отличают их от ПрО традиционных систем управления и обработки данных, являются свойства интеллектуальности ПрО, характерные для СИИ в целом. Основным назначением ПрО СИИ является ориентация на символьную обработку информации и решение трудно формализуемых задач, которые не могут быть описаны в математической форме и не имеют алгоритмического решения.
1.4 ВЫВОДЫ ПО РАЗДЕЛУ
2 РАЗРАБОТКА МЕТОДИКИ ИСПОЛЬЗОВАНИЯ СИСТЕМ ИСКУССТВЕННОГО ИНТЕЛЛЕКТА ПРИ ОБРАБОТКЕ АНКЕТНЫХ ДАННЫХ
2.1 ПРИМЕНЕНИЕ СИСТЕМ ИСКУССТВЕННОГО ИНТЕЛЛЕКТА ПРИ СБОРЕ И ОБРАБОТКЕ ДАННЫХ
Машинное обучение (англ. machine learning) – обширный подраздел искусственного интеллекта, математическая дисциплина, использующая разделы математической статистики, численных методов оптимизации, теории вероятностей, дискретного анализа и извлекающая закономерности из данных. Машинное обучение уже нашло применение в следующих областях: в биоинформатике, в медицине (медицинская диагностика), в геологии и геофизике, в социологии, в экономике (кредитный скоринг, предсказание оттока клиентов, обнаружение мошенничества, биржевой технический анализ, биржевой надзор), в технике (техническая диагностика, робототехника, компьютерное зрение, распознавание речи), в офисной автоматизации (распознавание текста, обнаружение спама, категоризация документов, распознавание рукописного ввода). Сфера применений машинного обучения постоянно расширяется. Повсеместная информатизация приводит к накоплению огромных объемов данных в науке, производстве, бизнесе, транспорте, здравоохранении. Возникающие при этом задачи прогнозирования, управления и принятия решений часто сводятся к обучению по прецедентам. Раньше, когда таких данных не было, эти задачи либо вообще не ставились, либо решались совершенно другими методами.
Системы с машинным обучением и технологиями искусственного интеллекта предполагают, что программа проводит обработку данных не по заданным правилам, а создает эти правила сами. Такие системы помогают лучше распознавать тексты, изображения и голосовые команды. Поэтому в сфере рекрутинга они позволяют, например, лучше сканировать резюме и описания вакансий, а также создавать программы-ассистенты, которые будут отвечать на распространенные вопросы и давать первоначальную информацию.
Задача классификации – это определение принадлежности объекта наблюдения к определенному классу. При наличии множества объектов, у которых уже известна принадлежность к классам, можно построить алгоритм, который сможет определять, к какому из классов будет принадлежать новый объект. В терминах машинного обучения объекты с известной принадлежностью к классам называются обучающей выборкой, а задача определения принадлежности нового объекта к классу – классификацией. Алгоритм, с помощью которого определяется принадлежность к классу, – классификатор [37].
2.2 СИСТЕМЫ СБОРА И ООБРАБОТКИ ДАННЫХ
На первом этапе импортируем данные из google forms в Excel. Далее необходимо создать обучающую выборку, которая составлена мной как экспертом, то есть я разделила все анкеты на 2 группы: полезные и бесполезные. Под бесполезными анкетами понимаем анкеты, признаки которых принимают следующие значения:
-
количество отвеченных вопросов меньше пяти;
-
ответы на все вопросы одинаковые;
-
ответы (числа) идут в порядке возрастания/убывания с шагом 1;
-
в анкете присутствуют максимальные и минимальные числа (ответы).
В машинном обучении признаки описывают объект в доступной и понятной для компьютера форме.
Следующим этапом импортируем библиотеки pandas для удобной работы с данными и numpy для работы с числами (рисунок 3.1).
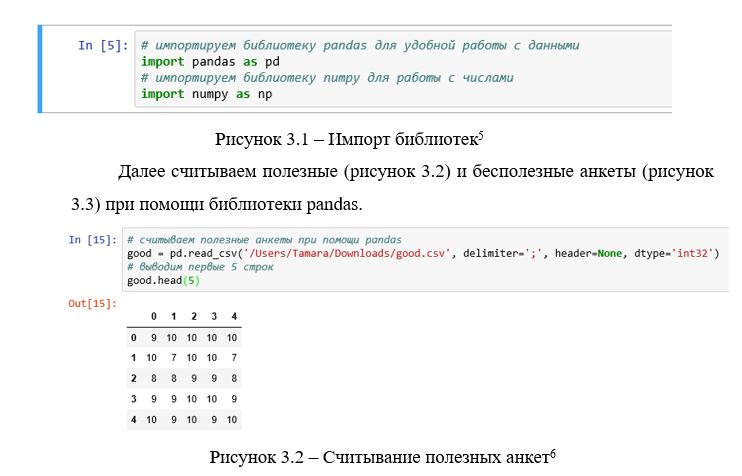
2.3 ВЫВОДЫ ПО РАЗДЕЛУ
3 ПРИМЕНЕНИЕ СИСТЕМ ИСКУССТВЕННОГО ИНТЕЛЛЕКТА ПРИ СБОРЕ И ОБРАБОТКЕ АНКЕТНЫХ ДАННЫХ
3.1 ОБЩАЯ ХАРАКТЕРИСТИКА ОРГАНИЗАЦИИ
Объектом рассмотрения данной магистерской диссертации является институт «Высшая школа экономики и менеджмента Уральского федерального университета им. первого Президента России Б.Н. Ельцина». ВШЭМ создана как полнопрофильное структурное подразделение УрФУ, где сосредоточена подготовка по всем основным (бакалавриат, магистратура) и дополнительным направлениям (программы МВА, программы профессиональной переподготовки и повышения квалификации) высшего профессионального образования, подготовка кадров высшей квалификации (аспирантура, докторантура) по укрупненной группе «Экономика и управление», а также фундаментальные и прикладные научные исследования и консалтинг в области экономики, менеджмента и промышленного бизнеса. ВШЭМ УрФУ выполняет функции бизнес-школы УрФУ.
ВШЭМ УрФУ создана на базе профильных подразделений Уральского федерального университета (факультет экономики и управления, факультет информационно-математических технологий и экономического моделирования, бизнес- школа), Уральского государственного университета им. А.М. Горького (экономическй факультет) с включением кафедр непрофильных подразделений университетов:
3.2 СИСТЕМА СБОРА И ОБРАБОТКИ ДАННЫХ ОПРОСА СТУДЕНТОВ «AS-IS»
На данный момент документовед обрабатывает все собранные анкетные данные, не фильтруя их. Процесс занимает достаточно большое количество времени. На входе - анкетные данные, на выходе - консолидированный отчёт. Участники процесса - документовед и программное обеспечение MS Excel. Упрвление представляется в виде рабочих планов групп, содержащих фамилию преподавателя, предмет и организационную форму обучения (рисунок 2.12).
При обработке ответов выполняются 3 основных бизнес-процесса (рисунок 2.13):
-
сбор данных;
-
обработка данных;
-
создание консолидированного отчёта.
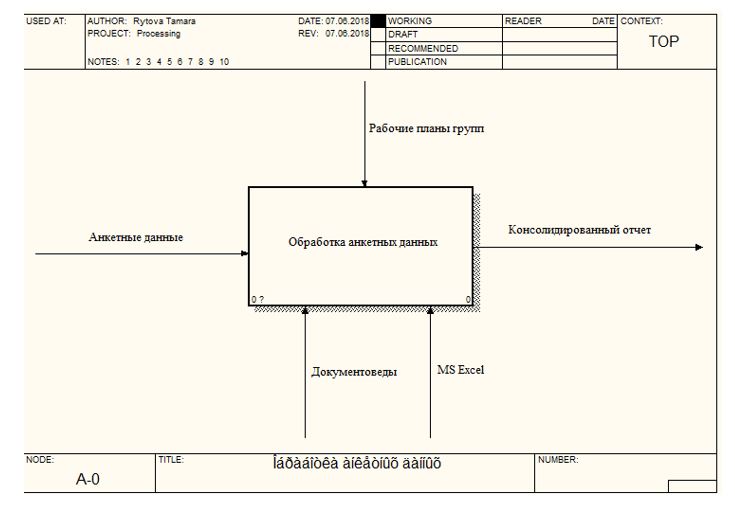
Рисунок 2.12 - Контекстная диаграмма «Обработка анкетных данных»
3.3 СИСТЕМА СБОРА И ОБРАБОТКИ ДАННЫХ ОПРОСА СТУДЕНТОВ «TO-BE»
По окончании пройденных курсов студент заполняет анкету о качестве обучения, оставляет свои комментарии. Зачастую качество результатов, полученных в ходе анкетирования, делает нецелесообразным дальнейшую их обработку. Большинство комментариев «бесполезны», их трудно понять и расшифровать. Многие респонденты для сокращения времени заполнения анкеты указывают одинаковые ответы, чередуют их, либо проставляют оценки по порядку, например, на вопрос 9 отвечают – 1, на вопрос 10 – 2, на вопрос 11 – 3 и т. д. Разумеется, такие заполненные анкеты не отражают действительного мнения респондента, бесполезны и не должны учитываться при обработке данных.
На данный момент документовед обрабатывает анкетные данные «вручную». И, скорее всего, анкеты с неверными ответами будут учтены в анализе. Даже если сотрудники установят правила исключать такие анкеты, то всегда имеет место быть человеческий фактор, и диспетчер включит такие данные опроса к обработке.
Можно сделать вывод о том, что для получения релевантных результатов нужно исключать заведомо неверные ответы на опросы путём применения методов интелектуальной обработки данных.
На рисунке 2.14 представлена диаграмма декомпозиции «Обработка анкетных данных» c использованием машинного обучения.
3.4 ЭКОНОМИЧЕСКО ОБОСНОВАНИЕ
Характеристика выпускной работы
В экономической части представлено экономическое обоснование магистерской диссертации «Применение искусственного интеллекта при обработке анкетных данных».
Целью данной части выпускной работы является экономическое обоснование внедрения системы искусственного интеллекта, доказывающее экономическую целесообразность затрат на его внедрение.
В экономической части будут посчитаны затраты на заработную плату, налоги, материальные и нематериальные расходы на этапах реализации и эксплуатации проекта, рассчитаны чистый приведенный доход, внутренняя норма доходности. А также в заключении будут представлены эффект в денежном эквиваленте от внедрения проекта и суммарная стоимость проекта.
Описание статей расходов
Разобьем процесс магистерской диссертации на этапы по каждому виду работ и определим ожидаемую трудоёмкость выполнения каждого вида работ.
Исполнители выпускной работы:
-
аналитик;
-
python-разработчик.
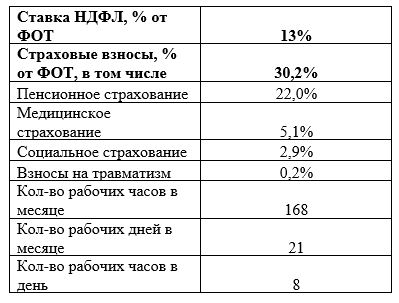
Во-первых, рассчитаем стоимость часа работы специалистов, задействованных в проекте. Вспомогательные величины для расчетов представлены в таблице 1.
Таблица 1 – Вспомогательные величины
3.5 ВЫВОДЫ ПО РАЗДЕЛУ
ЗАКЛЮЧЕНИЕ
Каждая современная организация оперирует большим объёмом данных, который нужно систематически обрабатывать. Для этой цели предприятия, как правило, используют информационные технологии, позволяющие автоматизировать некоторые рутинные, постоянно повторяющиеся операции.
Преимуществами автоматизации работы является следующее:
-
существенное сокращение числа ошибок в работе;
-
снижение затрат времени и сил на выполнение привычных операций;
-
существенное увеличение эффективности работы.
В ходе работы были выполнены следующие задачи:
-
рассмотрены теоретические основы систем сбора и обработки данных;
-
изучены системы искусственного интеллекта и программное обеспечение систем ИИ;
-
проанализирована деятельность службы диспетчеризации ВШЭМ УрФУ и предоставлено решение для более эффективной работы;
-
автоматизирован процесс отбора анкетных данных в дистрибутиве Python Anaconda с использованием алгоритмов машинного обучения;
-
определена эффективность автоматизации отбора анкетных данных для службы диспетчеризации ВШЭМ УрФУ.

